 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurity Law for Generalizable Neural TSP Solvers
May 07, 2025Achieving generalization in neural approaches across different scales and distributions remains a significant challenge for the Traveling Salesman Problem~(TSP). A key obstacle is that neural networks often fail to learn robust principles for identifying universal patterns and deriving optimal solutions from diverse instances. In this paper, we first uncover Purity Law (PuLa), a fundamental structural principle for optimal TSP solutions, defining that edge prevalence grows exponentially with the sparsity of surrounding vertices. Statistically validated across diverse instances, PuLa reveals a consistent bias toward local sparsity in global optima. Building on this insight, we propose Purity Policy Optimization~(PUPO), a novel training paradigm that explicitly aligns characteristics of neural solutions with PuLa during the solution construction process to enhance generalization. Extensive experiments demonstrate that PUPO can be seamlessly integrated with popular neural solvers, significantly enhancing their generalization performance without incurring additional computational overhead during inference.
PSDNet and DPDNet: Efficient channel expansion, Depthwise-Pointwise-Depthwise Inverted Bottleneck Block
Sep 03, 2019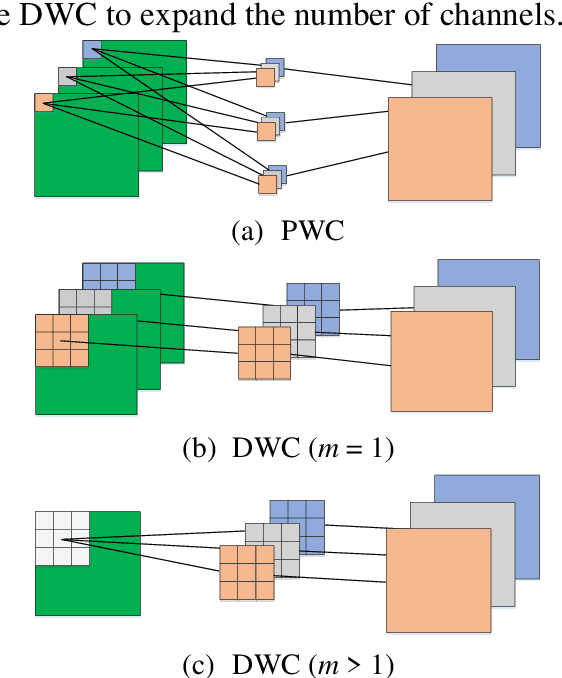

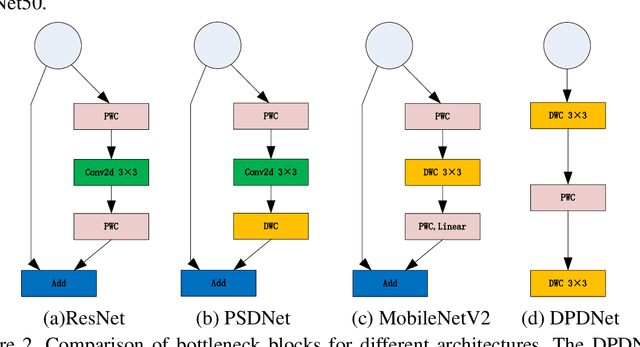

In many real-time applications, the deployment of deep neural networks is constrained by high computational cost and efficient lightweight neural networks are widely concerned. In this paper, we propose that depthwise convolution (DWC) is used to expand the number of channels in a bottleneck block, which is more efficient than 1 x 1 convolution. The proposed Pointwise-Standard-Depthwise network (PSDNet) based on channel expansion with DWC has fewer number of parameters, less computational cost and higher accuracy than corresponding ResNet on CIFAR datasets. To design more efficient lightweight concolutional neural netwok, Depthwise-Pointwise-Depthwise inverted bottleneck block (DPD block) is proposed and DPDNet is designed by stacking DPD block. Meanwhile, the number of parameters of DPDNet is only about 60% of that of MobileNetV2 for networks with the same number of layers, but can achieve approximated accuracy. Additionally, two hyperparameters of DPDNet can make the trade-off between accuracy and computational cost, which makes DPDNet suitable for diverse tasks. Furthermore, we find the networks with more DWC layers outperform the networks with more 1x1 convolution layers, which indicates that extracting spatial information is more important than combining channel information.